📌 프로젝트 개요
☐ 주관 : 2024 도서관 데이터 활용 공모전 (최우수상)
☐ 프로젝트 명 : OTT 콘텐츠 기반 도서 추천 대시보드
☐ 프로젝트 기간 : 24년 7월 ~ 24년 9월
☐ 인원 : 3명 (BOAZ 시각화 21&22기, 팀 보아주라)
☐ 활용 Tool : Notion, Python, Tableau, Figma, PPT
☐ 프로젝트 개요 : OTT 콘텐츠에 따른 맞춤형 도서 추천 시스템을 통해, 전반적인 독서율을 높이고 개인화된 독서 경험 제공
☐ 본인이 맡은 역할 :
- 자료 수집 및 전처리
- Selenium을 이용하여 도서 정보/평점/리뷰 크롤링
- 국민 독서 실태 현황 데이터 수집
- 대시보드 제작
- PPT 제작
☐ 성과/의의 :
- OTT 콘텐츠에 따른 맞춤형 도서 추천 시스템 구축을 통해, 도서 소비 촉진 기반 마련
- 국립중앙도서관을 위한 대시보드 활용 아이디어 제시
📑 프로젝트 내용
❓주제 선정 배경
지속적으로 독서율은 감소하고 있는 반면, OTT 소비는 꾸준하게 증가하고 있습니다. 또한, 도서와 OTT는 취향에 따라 다양한 콘텐츠를 접한다는 공통점을 가지고 있으나, 매체의 특성에 따라 소비량의 정도가 다른 것을 파악하여, 두 매체의 공통점을 기반으로 새로운 연결점을 제공하고자 했습니다.
이를 해결하기 위해, 크게 다음 두 가지의 목표를 세웠습니다.
- 독서 및 OTT 현황 파악
- 도서와 OTT의 연결성 강화
🔗 데이터 수집
📈 활용 데이터 목록
데이터 | 시점 | 출처 | 데이터 설명 및 목적 |
2024 인기대출 도서 1000권 | 2024. 1 ~ 2024. 7 | 도서관 정보나루 | 대출 인기 도서 도출 |
사서 추천 도서 | 2010. 3 ~ 2024. 8 | 국립중앙도서관 누리집 | 추천 도서의 다양성 확보 및 퀄리티 보장 |
도서 장르/평점/리뷰 | ~ 2024. 8 | 교보문고 | 도서 상세 설명 |
도서 줄거리 핵심 키워드 | 2024. 1 ~ 2024. 8 | 도서관 정보나루 + 누리집 | 도서 키워드 도출 |
OTT 콘텐츠별 추천 도서 | 2024. 1 ~ 2024. 8 | 도서관 정보나루 + 누리집 | 콘텐츠별 추천 도서 매칭 |
OTT별 인기 콘텐츠 | 2024. 7 ~ 2024. 8 | 키노라이츠 | 인기 콘텐츠 도출 |
도서 선호 분야 (종이책, 성인) | 2021. 1 ~ 2021. 12 | 문화체육관광부 | 성인 도서 선호 분야 파악 |
독서 매체별 독서시간 (성인) | 2021. 1 ~ 2021. 12 | 문화체육관광부 | 성인 독서 시간 파악 |
독서 빈도 (성인) | 2021. 1 ~ 2021. 12 | 문화체육관광부 | 성인 독서 빈도 파악 |
독서 장애 요인 (성인, 학생) | 2021. 1 ~ 2021. 12 | 문화체욱관광부 | 독서 장애 요인 파악 |
종합 독서량 (성인, 학생) | 2019. 1 ~ 2021. 12 | 문화체육관광부 | 연간 종합 독서량 파악 |
독서인구 | 2003 ~ 2024 | 통계청 | 독서 인구 및 1인당 평균 독서 건수 파악 |
온라인동영상제공서비스 OTT 이용 빈도 | 2015. 1 ~ 2023. 12 | 정보통신정책연구원 | OTT 이용 빈도 파악 |
최근 3개월 OTT 서비스 이용 경험 여부 | 2021. 1 ~ 2023. 12 | 정보통신정책연구원 | OTT 이용 경험 여부 파악 |
활용한 모든 데이터는, 프로젝트 진행 당시 기준 최신 데이터로 수집하였습니다.
🙋🏻♀️ 본인이 맡은 역할
⓵ 교보문고를 통해 도서 장르/평점/리뷰 크롤링
도서관 정보나루, 국립중앙도서관 누리집에 실려있는 도서들에 대해, 교보문고를 통해 도서의 장르/평점/리뷰 크롤링을 진행하였습니다.
from selenium import webdriver from selenium.webdriver.common.by import By from selenium.webdriver.support.ui import WebDriverWait from selenium.webdriver.support import expected_conditions as EC import pandas as pd import numpy as np import re import time bn = pd.read_excel('/Users/hyewon/Downloads/사서추천도서 목록_2024-09-14.xls') def collect_reviews_from_bn(start_idx, end_idx): # 크롬 드라이버 경로를 지정하고 드라이버 실행 driver = webdriver.Chrome() # 크롬 드라이버 경로 설정 필요 wait = WebDriverWait(driver, 10) # 최대 10초 대기 # 국립중앙도서관 URL 접속 url = 'https://nl.go.kr/NL/contents/N20500000000.do' driver.get(url) try: # 주어진 인덱스 범위의 책에 대해서만 반복 (start_idx부터 end_idx까지) for index, row in bn.iloc[start_idx:end_idx].iterrows(): book_title = row['서명'] # '서명' 값 추출 try: # 검색창에 서명 값 입력 (ID 확인 후 수정 필요) search_box = wait.until(EC.presence_of_element_located((By.ID, 'schStr'))) # 검색창의 ID search_box.clear() # 이전 검색 내용 지우기 search_box.send_keys(book_title) # '서명' 값 입력 # 검색어를 치고 엔터키를 입력하는 것과 같은 효과 search_box.send_keys("\n") # 엔터키 입력 # 검색 결과 페이지에서 첫 번째 책 클릭 (XPATH 확인 후 수정 필요) first_book_image = wait.until(EC.element_to_be_clickable((By.XPATH, '//*[@id="list_tabpanel"]/div/ul/li/a/div/div[1]'))) first_book_image.click() # 세부 페이지로 이동 후, 페이지 로딩 대기 time.sleep(2) # 특정 요소 클릭 (XPATH 경로의 요소 클릭) clickable_element = wait.until(EC.element_to_be_clickable((By.XPATH, '//*[@id="sub_content"]/div[2]/div/div[1]/div[1]/div[1]/div[1]/div[2]/div/a'))) clickable_element.click() # 해당 요소 클릭 # 클릭 후 페이지 로딩 대기 time.sleep(2) # 세부 페이지에서 p 태그의 모든 텍스트 추출 p_elements = driver.find_elements(By.XPATH, '//*[@id="divSeoji"]/div/div[1]/div/p') # 모든 p 태그 선택 # 추출한 p 태그 텍스트를 저장할 리스트 p_texts = [p.text for p in p_elements] # 각 p 태그에 해당하는 열을 동적으로 생성 (p1, p2, p3, ... 형식) for i, text in enumerate(p_texts): column_name = f'p{i + 1}' # 열 이름 생성 (p1, p2, ...) if column_name not in bn.columns: # 만약 열이 존재하지 않으면 새로 추가 bn[column_name] = None bn.at[index, column_name] = text # 해당 열에 텍스트 값 저장 except Exception as e: print(f"책 '{book_title}' 처리 중 오류 발생: {e}") continue # 오류가 발생해도 다음 책으로 넘어가기 # 다음 검색을 위해 이전 페이지로 돌아가기 try: driver.back() time.sleep(2) except Exception as e: print(f"페이지 이동 중 오류 발생: {e}") driver.get(url) # 만약 페이지 이동에 실패하면 다시 URL로 이동 time.sleep(2) except Exception as e: print(f"전체 프로세스 중 오류 발생: {e}") finally: # 브라우저 닫기 driver.quit() # ISBN 추출 함수 def extract_isbn_number(row): isbn_pattern = r'(97[89][\d\-]+)' for col in ['p4', 'p5']: if pd.notna(row.get(col)): match = re.search(isbn_pattern, row[col]) if match: return match.group(0).replace('-', '') return None # 리뷰 수집 collect_reviews_from_bn(start_idx=584, end_idx=800) # ISBN 추출 및 추가 bn['isbn'] = bn.apply(extract_isbn_number, axis=1) # 결과 저장 bn.to_csv('/Users/hyewon/Downloads/사서추천도서 목록_isbn처리완료.csv', index=False) ---- 여기 밑에서부터는 내 코드 # ISBN 번호 추출 함수 def extract_isbn_number(row): # 'p4'와 'p5'에서 ISBN이 있는지 확인하고 숫자만 추출 isbn_pattern = r'(97[89][\d\-]+)' # '978' 또는 '979'로 시작하는 패턴 if pd.notna(row['p4']): match = re.search(isbn_pattern, row['p4']) if match: return match.group(0).replace('-', '') # ISBN 값에서 '-' 제거하여 반환 if pd.notna(row['p5']): match = re.search(isbn_pattern, row['p5']) if match: return match.group(0).replace('-', '') # ISBN 값에서 '-' 제거하여 반환 return None # 'p4' 또는 'p5'에서 ISBN 값을 추출하여 'isbn' 열에 저장 bn_isbn['isbn'] = bn_isbn.apply(extract_isbn_number, axis=1) bn_isbn bn_isbn.to_csv('/Users/hyewon/Downloads/사서추천도서 목록_isbn처리완료.csv')
⓶ 국민 독서 실태, 도서 추천 대시보드 제작
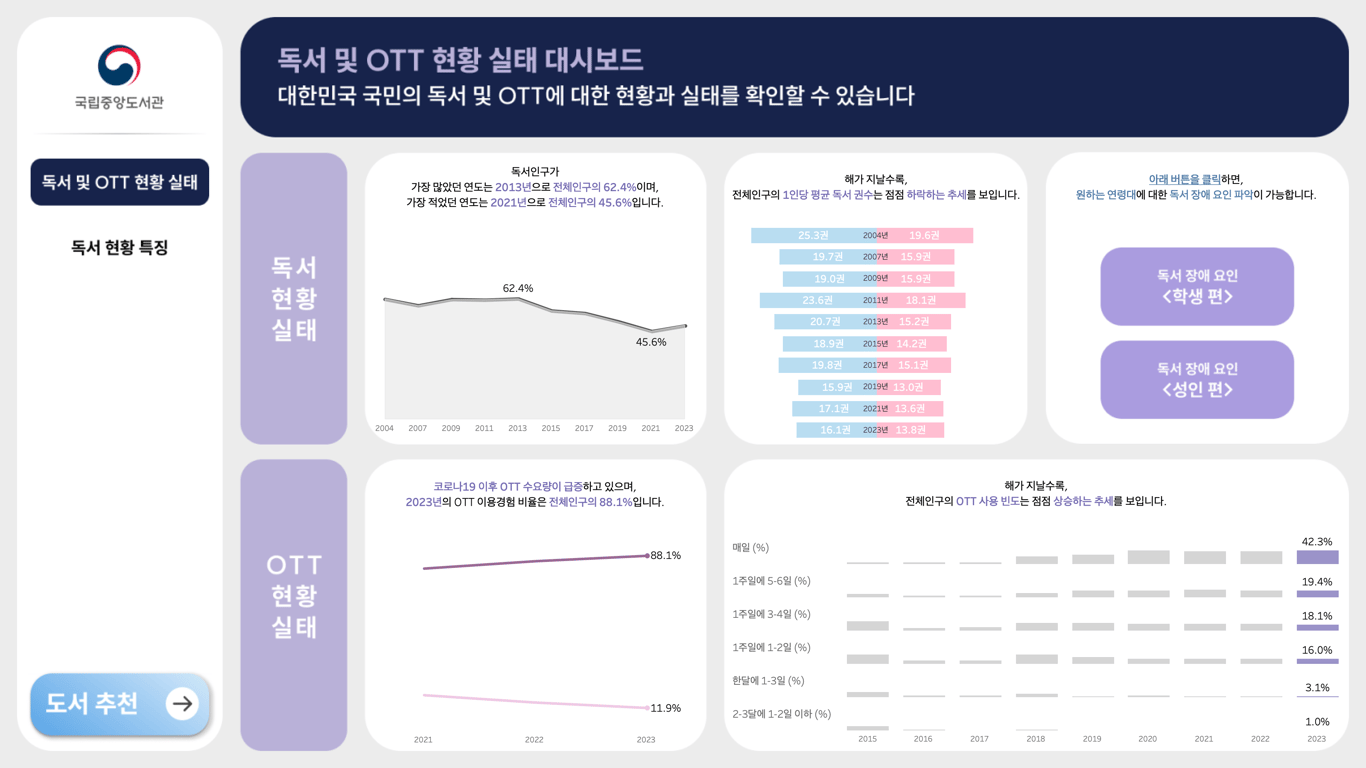
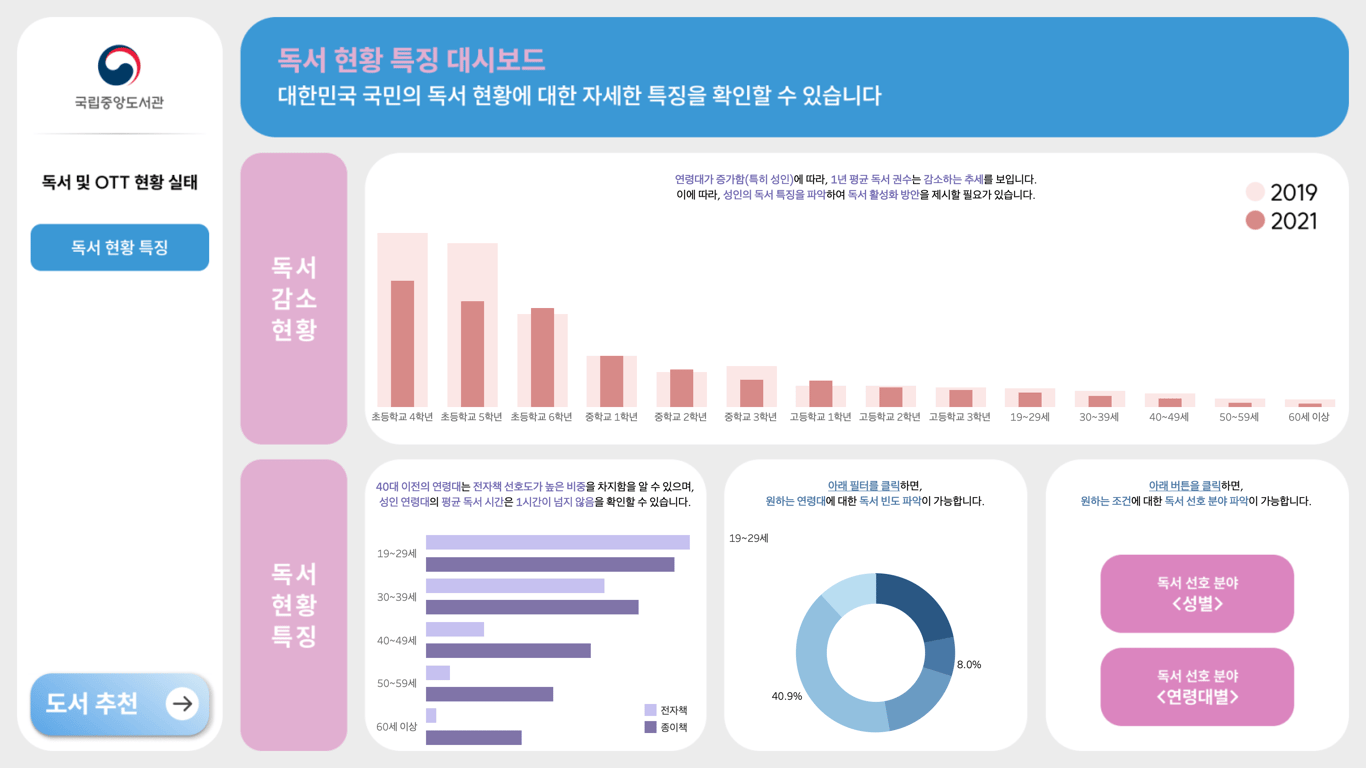
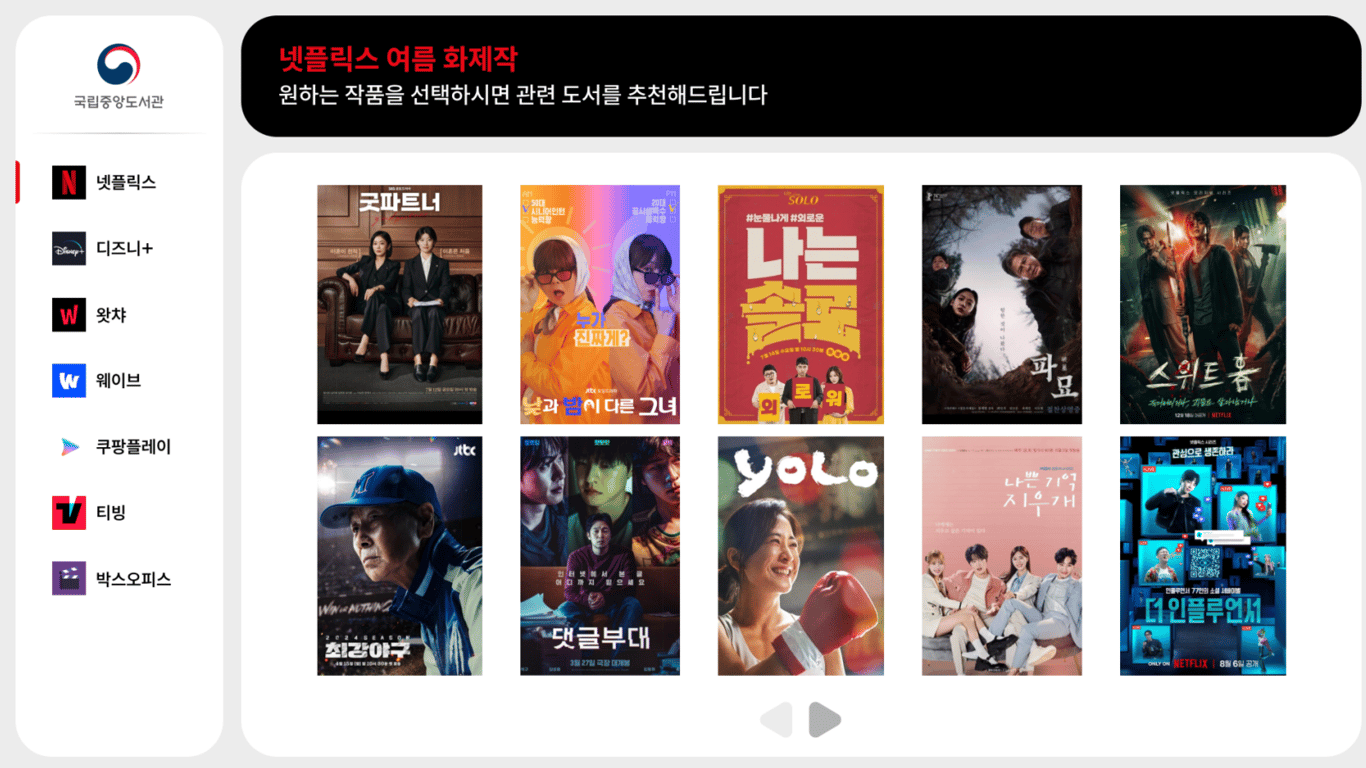
국민 독서 실태 및 OTT 이용 현황 확인을 위한 대시보드와, 올 여름 OTT 인기 콘텐츠 및 추천 도서를 제공해주는 대시보드를 제작하였습니다.


💡성과/의의
📍대시보드 인사이트
제작한 총 3개의 대시보드별 인사이트는 다음과 같습니다.
독서 및 OTT 현황 파악 대시보드
- 1인당 평균 독서 권수는 점차 하락하며, 2023년 기준 남성 16.1권 여성 13.8권의 독서를 소비.
- OTT 사용 빈도는 점차 상승하며, 2023년 기준 매일 이용하는 인구는 전체 인구의 42.3%임.
독서 현황 특징 대시보드
- 연령이 증가함에 따라, 1년 평균 독서 권수는 감소하는 추세.
- 40대 이전의 연령대는 전자책 선호도가 높은 비중을 차지하며, 모든 연령대의 전차잭 수요 증가.
- 셩인 연령대의 평균 독서시간은 1시간이 넘지 않음.
OTT 인기 플랫폼 기반 도서 추천 대시보드
- 원하는 OTT 플랫폼 및 인기 콘텐츠를 선택할 수 있게 배치.
- 원하는 콘텐츠를 선택했을 경우, 추천 도서 5권에 대한 상세 정보 표시.
→ ‘나는 솔로’ 선택 시, ‘우리는 여전히 삶을 사랑하는가’와 같은 사랑 이야기를 주제로 다룬 책이 추천된다. 책 소개 뿐만 아니라 독자들의 생생한 리뷰도 함께 제공함에 따라, 추천 받은 사람이 해당 책을 결정함에 추가적인 도움을 제공한다.
📍프로젝트 의의
진행한 프로젝트 의의는 다음과 같습니다.
- 원인 분석을 통한 큐레이션의 필요성
- 도서와 OTT는 매체의 특성에 따라 소비량이 다르나, 취향에 따라 다양한 콘텐츠를 접한다는 공통점을 기반으로 새로운 연결점을 제공하고자 하였습니다.
- 본인이 즐겨서 보는 OTT의 인기 콘텐츠를 통해, 해당 콘텐츠와 유사한 도서를 추천하는 대시보드를 제공함으로써, 더 나아지는 독서율에 기여하고자 하였습니다.
- 국립중앙도서관의 2024 주요업무추진계획 아이디어 제공
- ‘신뢰도 높은 데이터 구축과 큐레이션 강화’, ‘디지털 시민성 강화와 첨단기술 적용 정보서비스 강화’를 추진과제로 삼은 국립중앙도서관 측에 아이디어를 제공하였습니다.
- 국립중앙도서관 홈페이지 내, OTT 인기 콘텐츠 기반 도서 추천 대시보드를 임베딩함으로써, 매월마다 남녀노소 불문하고 다양한 도서 추천 서비스 경험을 제공하고자 하였습니다.
📍아이디어 결론
[아이디어] 국립중앙도서관 2024 주요업무추진계획의 아이디어 제공
- 배경
- 추진과제 1. [담고] 지식을 지혜로 담다
: 신뢰도 높은 데이터 구축과 큐레이션 강화 - 추진과제 2. [나누다] 국민과 함께 나누다
: 디지털 시민성 강화와 첨단기술 적용 정보서비스 강화
국립중앙도서관 2025 주요업무추진계획은 다음과 같습니다.
- 운영
- ‘추천도서’ 신규 코너 생성
- 세부 항목 고도화
국립중앙도서관 홈페이지 내, ‘OTT 인기 콘텐츠 기반 도서 추천 대시보드’를 임베딩합니다.
- 의의
- 누구나 이용 가능한 도서 추천 서비스
- 매월 기대되는 도서 추천 서비스
운영에 대한 의의는 다음과 같습니다.
: OTT 콘텐츠 기반 맞춤형 도서 추천 대시보드를 임베딩함으로써, 신선한 도서 추천 서비스를 제공한다.
: 정교화된 추천 서비스와 매월 달라지는 인기 OTT 콘텐츠는, 더 다양한 도서 추천 서비스 경험을 제공한다.
💬 회고
➕ 보완할 점
- OTT 콘텐츠의 제목 및 줄거리가 애매한 작품의 경우, 도서 추천 알고리즘의 정확도가 다른 콘텐츠들에 비해 다소 부정확한 부분이 아쉬웠습니다.
- 더 많은 도서 정보를 가져오고 더 긴 기간의 OTT 콘텐츠 정보를 가져와서, 더욱 다양한 도서 추천 서비스를 기획하는 것이 목표입니다.
🚶🏻♀️➡️ 성장한 점
- 추천 서비스에 관심이 많았는데, 좋아하는 카테고리인 ‘도서’를 추천하는 대시보드를 제작할 수 있게 되어 더욱 의미있었습니다.
- 시각화 하는 과정을 통해 점차 감소하는 독서율을 몸소 느꼈으며, 이를 발전시켜 나갈 수 있는 아이디어를 제공할 수 있는 시간이 되었습니다.
 Made with Bullet
Made with Bullet